Jotunn & Tyr
Generative AI
Highest Performance Inference
Lowest Deployment cost
What Is Generative AI
Generative AI refers to a subset of artificial intelligence (AI) techniques that involve creating or generating new data, content, or outputs that mimic or resemble human-generated content. Unlike traditional AI systems that are primarily used for classification, prediction, or optimization tasks, generative AI focuses on the creation of new content, such as images, text, music, or even videos.
Generative AI techniques typically involve deep learning models, particularly variants of neural networks like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and autoregressive models. These models are trained on large datasets to learn the underlying patterns and structures of the data, enabling them to generate new, realistic content that is similar to the training data.
Latency is crucial for generative AI inference for several reasons:
- Real-Time Applications: In many real-time applications such as video games, virtual reality, or live video streaming, low latency is essential to maintain a smooth and immersive user experience. Generative AI models used in these applications need to generate content quickly to respond to user inputs or changes in the environment.
- Interactive Systems: Generative AI is increasingly being used in interactive systems where users expect immediate feedback or responses. For example, in chatbots or virtual assistants, low latency ensures that responses are generated quickly, maintaining the conversational flow and user engagement.
- Dynamic Environments: In dynamic environments where conditions change rapidly, such as autonomous vehicles or robotics, generative AI models must be able to adapt and generate appropriate responses in real-time to ensure safe and effective operation.
- Scalability: Low latency becomes even more critical in systems with high scalability requirements, such as cloud-based services or distributed applications. Minimizing latency enables these systems to handle large numbers of concurrent users or requests efficiently.
- User Experience: Latency directly impacts the user experience, particularly in applications where users interact with generated content in real-time. High latency can lead to delays, interruptions, or a sense of disconnection, ultimately diminishing the quality of the user experience.
- Feedback Loops: In some generative AI systems, such as those using reinforcement learning, low latency is necessary to maintain fast feedback loops between actions taken by the model and the resulting outcomes. This enables the model to learn and improve more rapidly.
Reducing latency in generative AI inference often involves optimizing the model architecture, leveraging hardware acceleration (such as specialized AI chips), implementing efficient algorithms, and optimizing the deployment infrastructure. Balancing the trade-offs between latency, model complexity, and computational resources is essential to achieve optimal performance in generative AI systems.
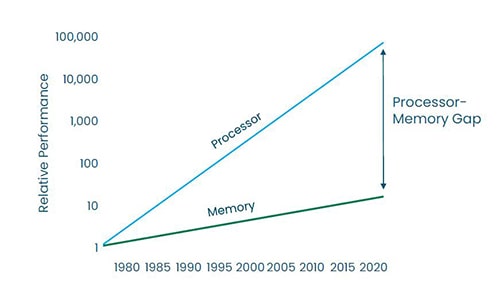
The "Memory Wall"
Why Generative AI software is ready but hardware not
Jotunn8
Cloud and On-Premise Inference
Any Algorithm
Any Host processor
Fully programmable Companion Chip

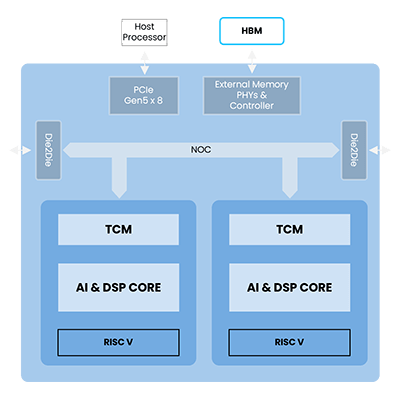
Fully programmable
- 16 cores
- High-level programming throughout
- Algorithm agnostic
- GPT-3 processing on a single chip
AI & GP processing automatically selected layer-by-layer
- Minimizes latency and power consumption
- Increases flexibility
Very high performance
- Close to theory implementation efficiency
- Allows very large LLMs (eg. GPT-4) to be deployed at <$0.002/query
Specifications
- 6,400 Tflops* (fp8 Tensor Core)
- 1,600 Tflops* (fp16 Tensor Core)
- 100 Tflops (fp8)
- 50 Tflops (fp16)
- 25 Tflops (fp32)
- 192 GB on-chip memory
- 180W (peak power consumption)
* = sparsity
Tyr Family
Any Algorithm
Any Host processor
Fully programmable Companion Chip
Tyr4

Fully programmable
- 8 cores
- High-level programming throughout
AI & GP processing automatically selected layer-by-layer
Very high performance
- Close to theory implementation efficiency
Specifications
- 3,200 Tflops* (fp8 Tensorcore)
- 800 Tflops* (fp16 Tensorcore)
- 50 Tflops (fp8)
- 25 Tflops (fp16)
- 12 Tflops (fp32)
- 16 GB on-chip memory
- 60W (peak power consumption)
* = sparsity
Tyr2

Fully programmable
- 4 cores
- High-level programming throughout
AI & GP processing automatically selected layer-by-layer
Very high performance
- Close to theory implementation efficiency
Specifications
- 1,600 Tflops* (fp8 Tensorcore)
- 400 Tflops* (fp16 Tensorcore)
- 25 Tflops (fp8)
- 12 Tflops (fp16)
- 6 Tflops (fp32)
- 16 GB on-chip memory
- 30W (peak power consumption)
* = sparsity
Tyr1

Fully programmable
- 2 cores
- High-level programming throughout
AI & GP processing automatically selected layer-by-layer
Very high performance
- Close to theory implementation efficiency
Specifications
- 800 Tflops* (fp8 Tensorcore)
- 200 Tflops* (fp16 Tensorcore)
- 12 Tflops (fp8)
- 6 Tflops (fp16)
- 3 Tflops (fp32)
- 16 GB on-chip memory
- 10W (peak power consumption)
* = sparsity

