


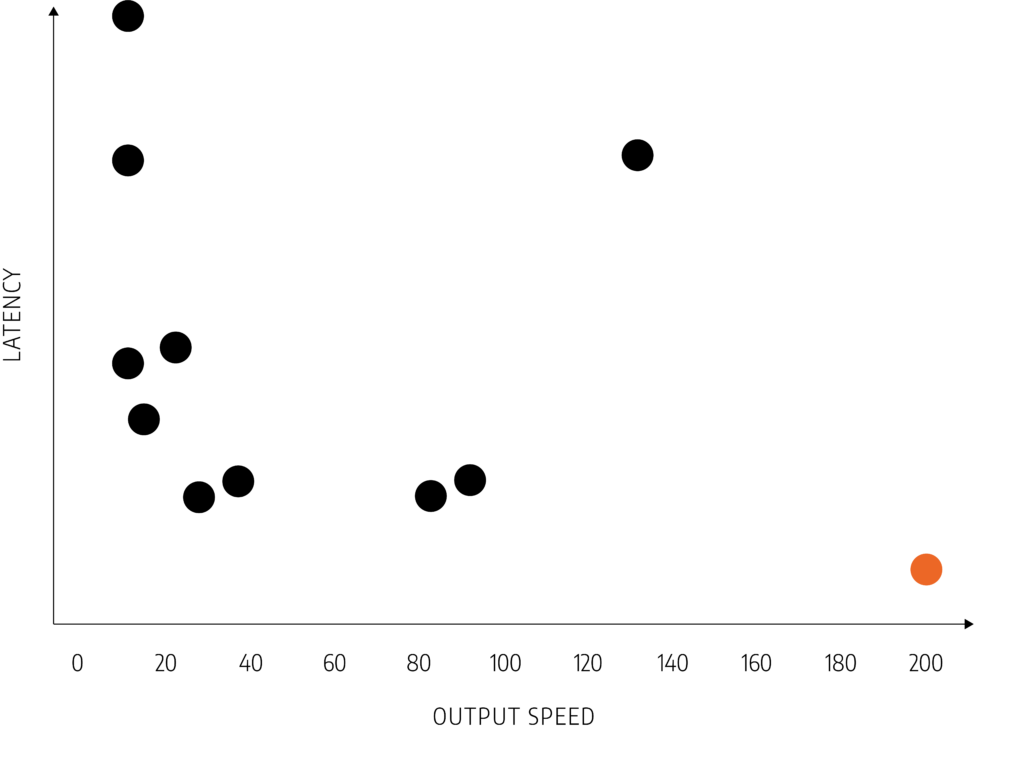

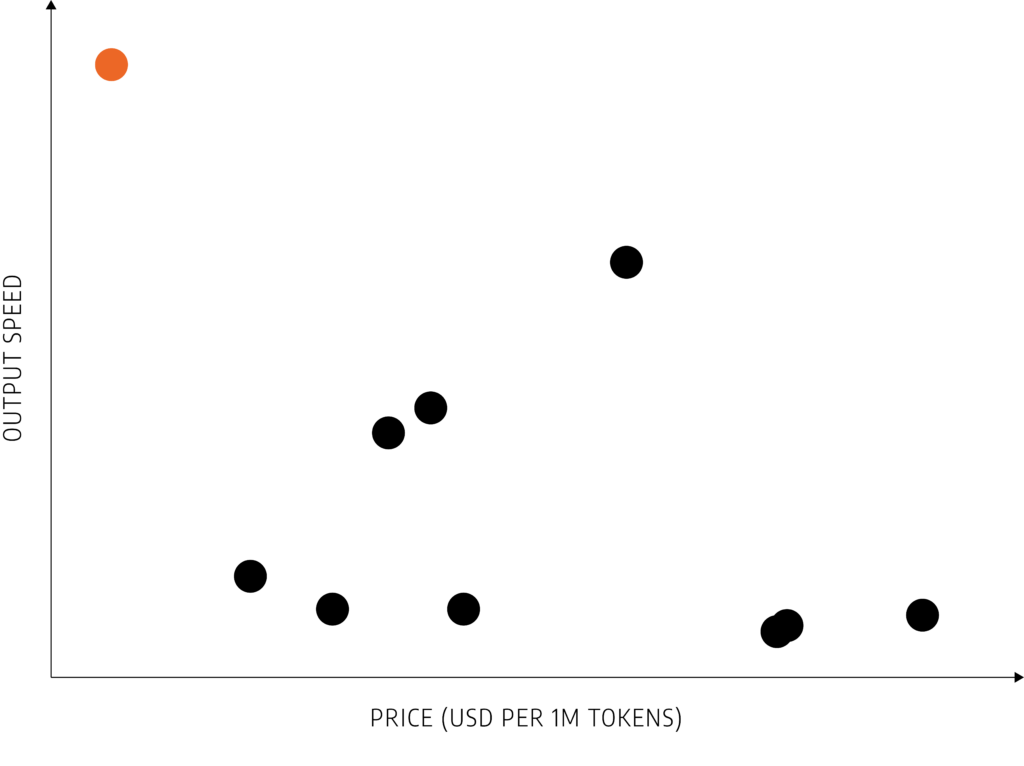


In modern data centers, success means deploying trained models with blistering speed, minimal cost, and effortless scalability. Designing and operating inference systems requires balancing key factors such as high throughput, low latency, optimized power consumption, and sustainable infrastructure. Achieving optimal performance while maintaining cost and energy efficiency is critical to meeting the growing demand for large-scale, real-time AI services across a variety of applications.
Unlock the full potential of your artificial intelligence investments with our high-performance inference solutions. Engineered for speed, efficiency, and scalability, our platform ensures your AI models deliver maximum impact—at lower operational costs and with a commitment to sustainability. Whether you’re scaling up deployments or optimizing existing infrastructure, we provide the technology and expertise to help you stay competitive and drive business growth.
This is not just faster inference. It’s a new foundation for AI at scale.
Khaled Maalej, co-founder and CEO of Vsora, was Laure Closier’s guest on French Tech this Monday, May 12. He discussed his company’s goals, which aim to produce artificial intelligence chips that offer unprecedented performance, consume less energy, and are more affordable than those of the world’s leading European companies, on Good Morning Business.
In the world of AI data centers, speed, efficiency, and scale aren’t optional—they’re everything. Jotunn8, our ultra-high-performance inference chip is built to deploy trained models with lightning-fast throughput, minimal cost, and maximum scalability. Designed around what matters most—performance, cost-efficiency, and sustainability—they deliver the power to run AI at scale, without compromise!
Why it matters: Critical for real-time applications like chatbots, fraud detection, and search.
Reasoning models, Generative AI and Agentic AI are increasingly being combined to build more capable and reliable systems. Generative AI provide flexibility and language fluency. Reasoning models provide rigor and correctness. Agentic frameworks provide autonomy and decision-making. The VSORA architecture enables smooth and easy integration of these algorithms, providing near-theory performance.
Why it matters: AI inference is often run at massive scale – reducing cost per inference is essential for business viability.
In today’s world, real-time decision-making is critical — and that’s where Edge AI delivers. Unlike traditional cloud-based AI, Edge AI processes data directly where it’s generated — on devices, machines, and sensors — enabling instant insights, lower latency, enhanced privacy, and reduced bandwidth costs. From autonomous vehicles to smart factories, Edge AI empowers industries to operate faster, smarter, and more securely. Tyr is built to unlock the full potential of Edge AI, delivering data-center-class performance in an ultra-efficient, compact form — bringing advanced AI capabilities to the very edge of your operations.
French Tech: Vsora Designs AI Chips – May 12
Khaled Maalej, co-founder and CEO of Vsora, was the guest of Laure Closier on French Tech this Monday, May 12. He spoke about the company’s goals, which include producing artificial intelligence chips that deliver unprecedented performance while being more energy-efficient and more affordable than those of the global market leaders. The interview aired on Good Morning Business. Catch the show Monday through Friday and listen again via podcast.
Laure: It is now 8:23 on BFM Business and BFM Discovery during the Morning Economy program. Today’s topic: AI chips with unprecedented performance—more energy-efficient, more affordable than those from global leaders. That’s quite a project. Good morning, Khaled Maalej, co-founder and CEO of VSORA. Your challenge is to compete with NVIDIA, which is already tough, especially when you look at the struggles of microelectronics companies in France and Europe to develop such chips. What market segment are you targeting, and what are you doing differently?
Khaled: Yes, VSORA actually makes electronic chips for artificial intelligence—circuits that provide computing capabilities equivalent to those of NVIDIA or AMD today. What sets us apart is that we focus solely on inference. AI has two main components: training, where algorithms are created—that’s not our focus—and inference, where those trained algorithms are used. That’s where GPUs are typically used. We’re focused on that second part. The big market challenge in inference is reducing the cost of computation, of processing queries. VSORA’s positioning is precisely in this area. What distinguishes us from other chips today is our computing efficiency. We offer chips with very high computing capacity, and we also allow for highly efficient arithmetic utilization embedded in the circuits. That’s what significantly lowers the cost of inference.
Speaker 3: But is this still just a project, a deep-tech concept, or is it already a working product? I ask because it seems a bit naïve, but we sincerely wish you success. How can a company of your size achieve what NVIDIA—with tens of billions of dollars—has not?
Laure: You just raised €40 million from Otium, which helps. But still…
Khaled: Right, we’re not talking billions, as you said. What’s changed today is chip architecture. Companies like NVIDIA have architectures that offer a certain performance, which works well today—the tech is solid. But there’s still a performance gap. We’ve developed an architecture that bridges that gap. That’s our core differentiator.
Speaker 3: So you’re saying that for them to achieve the same performance, they’d need to completely overhaul their architecture, which would be very costly?
Khaled: Exactly. That’s not easy for large companies. It’s always possible, but it’s not simple for them. That’s where we come in—with a solution to that problem.
Laure: Who are your direct clients?
Khaled: The end customers are data center operators. But we don’t sell directly to them. We sell to the companies that build the servers, who then sell to the data centers.
Laure: So you’re going up against NVIDIA in those tenders, I imagine?
Khaled: We don’t have a chip ready yet. That’s what the funding is for—to go into production. But yes, we will face them. Just to give an idea: ChatGPT currently handles about 5,000 requests per second, which is a lot. But compared to Google, which handles 100,000 requests per second, it’s very little. The market needs to scale from 5,000 to 100,000 requests per second. There’s a real need for technical solutions to lower the cost of that jump. And that’s where we come in.
Laure: So you’re the answer?
Khaled: Yes, we provide that answer.
Speaker 3: So maybe in a year or so, when I submit a request to ChatGPT, it will go through your chip?
Khaled: That’s the goal.
Speaker 3: That would be amazing.
Laure: You’re saying a year? Toni Morel?
Khaled: Even less than that.
Laure: Less than a year?
Khaled: Yes, our chip will be ready before the end of the year. It should be available in Q1 or Q2 of next year.
Speaker 3: You’re not manufacturing the chip yourself—you’re what’s called a fabless company, right? So a foundry will produce it?
Khaled: Exactly. Like everyone else, we use TSMC, the Taiwanese company. There are two key technologies involved: the silicon node, which must be very small—hence TSMC—and the packaging. High-performance chips with a lot of embedded memory require advanced packaging technologies.
Speaker 3: Is there also a sovereignty angle to this? I imagine that’s part of your pitch.
Laure: Probably your top marketing argument.
Khaled: Yes, sovereignty is very important. Hardware and AI chips are becoming strategic economic weapons. Today, we’re the only European company able to offer a chip with this level of performance and to demonstrate it against the major players.
Laure: Does that argument work? Or in the end, is cost still the deciding factor?
Khaled: Cost always wins over sovereignty. But the sovereignty argument is gaining traction at the European Commission. When Europe invests €20–40 billion in data centers, 80% of that money currently flows to the U.S. Having a European solution helps retain value within the European economy.
Laure: Still, you can’t be too far off in pricing, otherwise it won’t work. Sovereignty only becomes a serious argument when the price is right. Thank you very much, Khaled Maalej, for joining us this morning on Morning Economy.
Unmatched Performance at the Edge with Edge AI.
Fully programmable
Algorithm agnostic
Host processor agnostic
RISC-V core to offload & run AI completely on-chip
Tyr 4
fp8: 1600 Tflops
fp16: 400 Tflops
Tyr 2
fp8: 800 Tflops
fp16: 200 Tflops
Tyr 4
fp8/int8: 50 Tflops
fp16/int16: 25 Tflops
fp32/int32: 12 Tflops
Tyr 2
fp8/int8: 25 Tflops
fp16/int16: 12 Tflops
fp32/int32: 6 Tflops
Close to theory efficiency
Fully programmable
Algorithm agnostic
Host processor agnostic
RISC-V cores to offload host
& run AI completely on-chip.
fp8: 3200 Tflops
fp16: 800 Tflops
fp8/int8: 100 Tflops
fp16/int16: 50 Tflops
fp32/int32: 25 Tflops
Close to theory efficiency